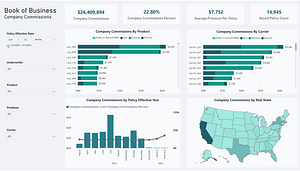
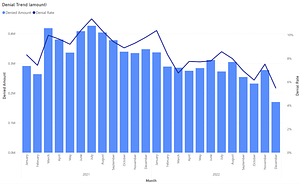
In part one of this series, Measuring the Cost of Doing Business with Insufficient Analytics, I referenced a series of studies conducted over the past five years showing that data analysts spend about 80% of their time organizing data. They devote only one day per week to analyzing data and generating reports, suggesting that their job function might be more appropriately named “data manipulator.”
To solve this problem, one must first understand the causes. To begin with, we can say with confidence that the cause is not a lack of data. On the contrary, it is by investigating the huge amounts of data available for analysis that we begin to see the underlying causes. For no meaningful analysis can begin, and no insights can be developed, until the data can be consumed using available tools. For most analysts, these tools include Excel and possibly one or more data visualization or data analysis tools. But none of these tools can consume raw data with any level of success. The problem, therefore, lies not in a lack of available data, but in a lack of “reporting-ready” data.
While the underlying data issues may not be of great interest to some, it is instructive to review them, and in so doing we can devise a strategy to overcome them. If our goal is to provide the analyst with reporting-ready data then we need to identify exactly what makes it not useful for reporting. Here are the top five reasons your data analyst can’t analyze the data…
Reason #1 – Data is stored in a way that’s hard to query
At the core of the problem is the issue of database structure. In an ideal world, the various systems that capture and store transactional data throughout the enterprise would keep it organized in a way that makes it easy to query. But instead, they organize data in what might appear to be a convoluted database structure, making it hard to understand and analyze. This is done for good reason, of course. The relational databases within these applications are structured in a way that makes adding and modifying records as fast as possible, and stores data efficiently. Using this approach, referred to as a normalized database model, ensures that customers and employees interacting with applications and websites experience high performance and short wait times. While a few analytics software vendors are starting to address this issue, it is still nearly impossible to deliver high-quality analytics across the enterprise without first extracting the data from source systems and reorganizing it.
Unfortunately, while converting the data from a normalized model into a different model that is more appropriate for reporting is a critical step, this alone does not result in “reporting-ready” data. To help data analysts reclaim the four days a week they spend manipulating data there are other issues that must also be addressed.
Reason #2 – Data is spread across multiple databases and must be integrated
A typical business has several transactional systems, each with a database that contains customer, vendor or employee activity data. Often, multiple systems may contain different types of data pertaining to a single entity such as a customer. Only by combining data from each system can you create an accurate picture of what is happening so that it can be analyzed and improved.
Unfortunately, data from one system may not match up easily with data from another system. Systems may use different IDs, use different names for the same entities, store data at different time intervals (i.e. hourly versus daily), or use different hierarchies (i.e. different sales territories or org structures), among other differences. Forcing all this data into a single database without adequately aligning it accomplishes very little. Instead, all of the differences must first be identified, then resolved one at a time by agreeing to and applying business rules to standardize the data.
Reason #3 – Some of the data is ”dirty”
As transactional systems are used over a number of years, it is quite common for users to run into limitations where the existing data fields in the system no longer meet the specific needs of the business. When this happens, clever users will always find a way around the limitation. More often than not this means using a field for something other than its intended purpose, or leveraging a free-text field to hold critical data. The result is data that needs to be interpreted before it can be clearly understood or used for reporting. Here again, business rules must be created and applied to remove or correct inaccurate or misleading data and parse out useful data where possible.
Reason #4 – Data usually needs to be grouped for filtering
Most data analysis won’t concern all of the available data. Instead, analysts typically want to see one or more subsets of the data. Similarly, analysts often want to see how various attributes (such as customer age group) affect results, but the groups and subgroups needed to make this possible are usually nowhere to be found and must be created every time analysis is done. By agreeing on and applying business rules in advance, a company can eliminate this busy work. As an added benefit this approach also ensures that the same grouping logic (such as the definition of value bands for age ranges) is used consistently over time and across the enterprise.
Reason #5 – Data needs to be aggregated and summarized
Even in a perfect world where the data is integrated, cleaned and grouped, this only enables the most basic forms of reporting. Managers will still lack the information they need to make informed decisions. This is because nearly all useful data analysis depends on data that doesn’t even exist in the source systems. Decision makers need to know the average account size, or the frequency of purchase, or the likelihood of making a sale, and this type of information must be created using calculations ranging from simple aggregation all the way to complex algorithmic models that produce predictive scores. In some cases this work belongs in the hands of the analyst, but the majority is routine busy work that must be run every time a data set is prepared for analysis, placing yet another demand on the analyst’s time.
In summary, the problem is clear – nearly all data requires various forms of manipulation before it can be useful for analytics. But if today’s reporting tools can’t adequately resolve the underlying data challenges, where does that leave us? Well, the solution certainly isn’t to buy expensive software expecting world-class analytics to magically appear. On the contrary, in most cases reporting software should only be purchased after the underlying data issues are resolved, or as part of a complete solution that takes this need into account. Fortunately there is a proven technique that’s been used time and again by some of the most successful companies in the world to overcome this challenge.
You can read part three of this series to learn about The Key to Analytics that Everyone Should Understand.