What are data solutions?
At LeapFrogBI we use the term data solution to refer to the portion of the overall analytics system that acquires data and makes it report-ready. The data solution (not the reporting software) is the most important factor in determining what types of reporting can be produced, and by who.
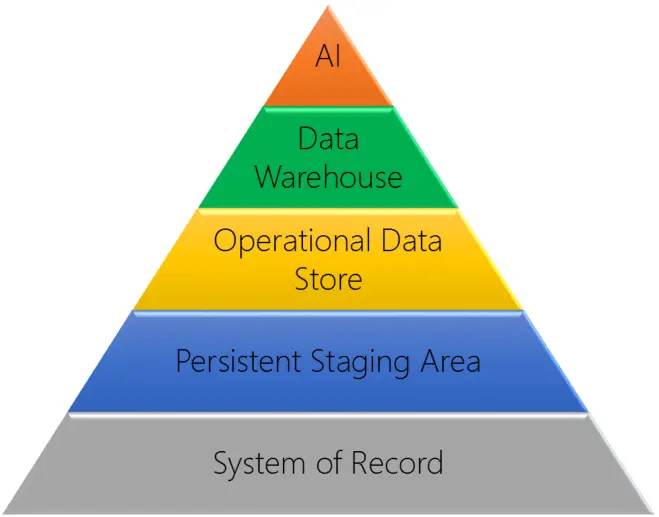
We group data solutions into five categories to provide a framework for analyzing and discussing different aspects of data acquisition, integration and transformation. You can think of each category as a levels of a pyramid that increase in complexity and capability as you move toward the top.
At the bottom of the pyramid is what we call the System of Record solution. The defining characteristic of this solution is that you use a reporting tool to directly access data in the operational system of record. With this approach, any and all data processing must be handled by the report tool itself. It’s a common way to get started with analytics because it can be implemented quickly and affordably. But it is not without its disadvantages. It places significant demand on the operational system, it limits the types of analysis that can be done and it places a very high burden on the report author to manipulate the data until it is accurate and meaningful.
The second level is what we call the Persistent Staging Area solution. At this level you introduce a database where you can store historical data outside of the system of record. You also get the opportunity to do some limited data processing as data moves between the system of record and the reporting tool. A simple staging area takes computing pressure off the operational system, and potentially reduces the demands on the reporting tool and the report author. It also allows you to track changes to (customer/product/organizational) attributes and enables data re-naming to improve usability. Of course, the added complexity requires additional development time and resources, but this approach is still a relatively fast and affordable approach with tremendous benefits.
The third level is what we call the Operational Data Store solution. We use this term to refer to a reporting database that may integrate data from more than one system of record, incorporate data transformation based on business rules or include summarized data. At this level significant data processing is happening between the system(s) of record and the reporting tool. It offers complete flexibility and tremendous power, but requires even more development and significant involvement from business stakeholders. Also, as the volume of data and complexity of the data processing that’s taking place increase, the performance of the operational data store may suffer.
The fourth level is what we refer to as the Data Warehouse solution. We use this term to refer to a database that includes all of the same features of an operational data store, but one in which the data has been reorganized into a dimensional data model. This data structure was developed specifically for reporting applications, and differs from the way data is organized in operational system databases. In operational systems the data is stored in a large number of tables which makes it very fast to add or modify a single record. But reporting queries typically require data from a large number of tables, thus requiring a a large number of table joins and resulting in very long processing times. The dimensional model uses a very small number of tables, reduces the number of joins in a query and significantly improves performance so most queries are resolved in just seconds. As an added benefit, dimensional models are logical and easily understood which further advances reporting initiatives by enabling self-service analysis by business users. A well-designed data warehouse can enable high-performance reporting against even the largest and most complex data sets, and is the gold standard for enterprise business intelligence.
At the top of the data solution pyramid is Artificial Intelligence. We use this term to refer additional data processing that occurs outside the data warehouse. This level allows for predictive and prescriptive models using traditional statistical techniques or newer self-learning tools. When such analysis is required, AI is the only solution, regardless of underlying data complexity or volume. While AI does not replace the data warehouse, it may produce scores and other data that gets loaded into the warehouse.