Loading a data warehouse requires that a mechanism be created for tracking which source system records have been processed and which are pending. ETL & ELT are very custom processes, but general design patterns are often repeated. In an ideal situation the data integration process will possess these traits:
- Collection of source system records can be executed independent of DW loading.
- Ability to queue records that do not meet load criteria. Retry on subsequent loads.
- Minimize resource needs by only processing each source system record one time.
By collecting and consolidating source system records without modification we are creating a new reliable source that supports critical data warehouse needs such as data persistence and rapid model changes. PSA also enables agile workflow by greatly reducing the amount of rework required when a model changes or is extended. These steps are called various names, but for the purpose of this post I will stick to LeapFrogBI standards and refer to them as stage & PSA. Stage is the pump and dump location. On each load the target stage table is truncated & loaded with new records. PSA (persistent staging area) is the consolidation area which stores all versions of all records (some archived) received without modification.
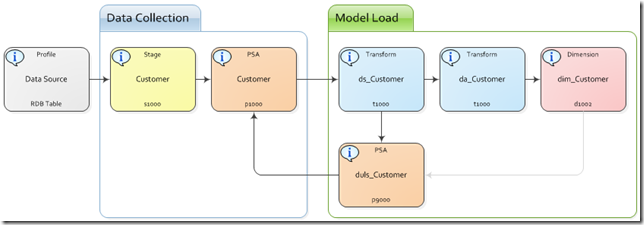
With a reliable source in place we can move forward and load the target model. The first step is to select the unprocessed records from PSA. How do we know which records are unprocessed? We create a field in PSA which contains a constant value, 0, meaning unprocessed. With this field in place we can simply select all records with a flag value equal to 0. After loading the target dimension or fact, we can then update PSA and set the flag to 1 (processed) so that it is not reprocessed on subsequent loads.
In the schematic there is a light grey line pointing from dim_Customer to duls_Customer (dimension update load status). This is a precedence constraint meaning that the duls_Customer component will not run unless the dimension load is successful. Since all load processes are handled within a transaction we can be sure that the system integrity will remain intact in the event of a failure.
Updating PSA is simple with ds_Customer (dimension source) in place. We inner join on a GUID (generated if needed) and update all load status flag values to 1. It is common that a single PSA will be used as the source for multiple dimensions or fact tables. This is handled by creating a load status field for each target object.
What if we do not want to load a record in a fact table if it does not have a related dimension record? This is the queue scenario described above. To facilitate this fuls_FactTable will inner join on the GUID and will filter on a business rule leaving only records that were loaded successfully to be updated in PSA. Of course, similar logic must also restrict the records that actually are loaded into the target fact table in this example.
Load status tracking should be kept as simple as possible while still getting the job done reliably. LeapFrogBI makes this process very simple by automating many of the tasks involved and enabling rapid prototyping.