Dimensional modeling (DM) places and emphasis on the end user’s experience. The goal is to create a data model that performs well and is simple to query. In many cases a star schema does a great job of accomplishing these goals. However, there are plenty of situations where a single fact table with direct relationships to dimensions is not the best solution. One such case exist when a fact table should relate to a dimension that is at a lower level of granularity. For example; a fact table that is at the patient grain (one record per patient) may need to relate to the diagnosis dimension (one record per diagnosis). This works well if there is only one diagnosis per patient, but when more than one diagnosis should relate to a single fact record we need to adjust our simple start schema to accommodate. A bridge table is used to bridge the gap between a fact table and a dimension at a lower grain.
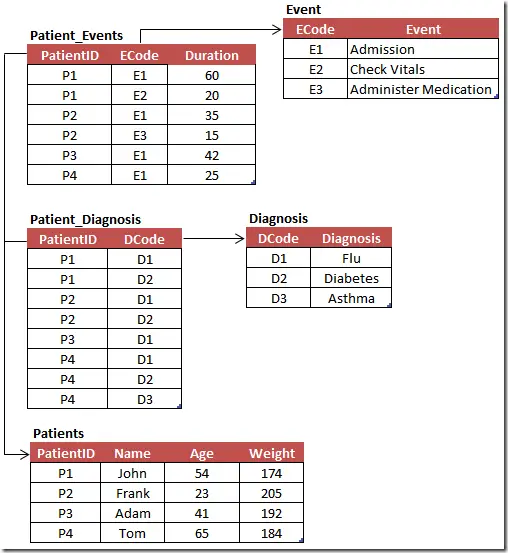
The following sample source system table structure will be used throughout this post. Notice that the Patient_Event table relates to the Patient and Event tables directly. There is also a table called Patient_Diagnosis which keeps track of each patient’s current set of diagnosis.
In this example we want to create a fact table that is at the patient, event, diagnosis grain so that users can quickly determine the duration of each related event. However, the source system provides duration data at the patient, event grain. To bring the data to lower grain (add diagnosis) we would need to somehow spread the duration value across all diagnosis for each distinct patient event value. This may be possible, but let’s look at another option. We could set the fact table’s grain at patient, event, diagnosis group. By doing so we do not need to manipulate the duration value which would likely complicate the end user’s experience.
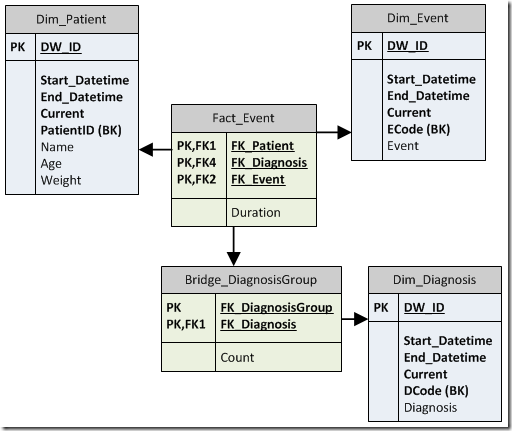
The following diagram describes the target data model. Notice that we have a single fact table with three foreign keys. The patient and event foreign key are standard relationship to dimension surrogate keys. The diagnosis foreign key is handled a little differently. We need to create and manage a diagnosis group dimension. This dimension is used when looking up the foreign key from our fact table for dimension groups.
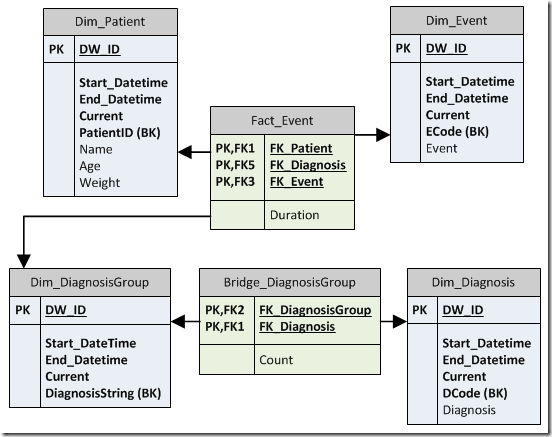
The diagnosis group dimension is not essential, however, to the end user. The bridge table resolves the many-to-many map between diagnosis groups and each diagnosis. Since the bridge table includes a foreign key to the diagnosis group dimension (same as in the fact table) users can join the fact table directly to the bridge table to get a list of all related diagnosis.
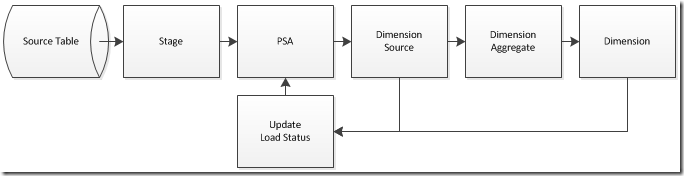
With this target model in mind we need to create a data flow that will build and maintain each table. The patient, event, and diagnosis dimension can be created in the typical manner.
1. Stage – Incremental extract from source table
2. PSA – Create historical store
3. Dimension Source – Select unprocessed records from PSA
4. Dimension Aggregate – Ensure data is at the desired grain for dimension load
5. Dimension – Load dimension
6. Update Load Status – Update PSA’s load status flag for dimension processing
The fact table (fact_event) and the bridge table (bridge_DiagnosisGroup) both require a foreign key to the diagnosis group dimension. Therefore, we must first create the diagnosis group dimension. Let’s take a closer look at the dimension source data and the desired format of the data once it is loaded in to the dimension.
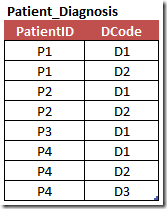
Our goal is for the dimension to contain one record for each unique combination of patient diagnosis. The source data is located in the patient_diagnosis table which contains one record per patient diagnosis.
The resulting dimension should contain the following records. The key is that the dimension key is set to the DString field. This field contains a distinct set of delimited diagnosis codes (DCode).

Creating the distinct list of delimited diagnosis codes requires that we convert multiple records into a concatenated string. For example, there are two records in the patient diagnosis source table with a patient ID equal to P1 and diagnosis codes of D1 & D2. We want to convert these two records into a string; D1|D2. There are several ways to accomplish this, but the below t-SQL is one of the best options for converting records into strings.
SELECT DISTINCT
PatientID,
DCodes,
(len(DCodes) - len(replace(DCodes, '|~|', '')))/3 + 1 as MemberCount
FROM Patient_Diagnosis p1
CROSS APPLY
(
SELECT stuff(
(SELECT '|~|' + DCode FROM Patient_Diagnosis p2
WHERE p2.PatientId = p1.PatientId
ORDER BY DCode
FOR XML PATH(''), TYPE).value('.', 'varchar(max)')
,1,3,'')
) D ( DCodes )
LeapFrogBI users can use the ”Records To String” transformation component template to generate this script automatically. Simply select the field to group by and the field to concatenate into a delimited string. The rest is handled by LeapFrogBI without further developer involvement. The below image is a screenshot of the ”Records to String” transform component definition.

The following output is created by the above script. Each record represents a distinct list of Patient IDs with that patient’s related diagnosis. This can be used as the source for our diagnosis group dimension. We can also join this output to the fact table source on PatientID to determine the DCodes for each fact which will be used to join to the diagnosis group dimension to retrieve foreign keys during the fact table load process.
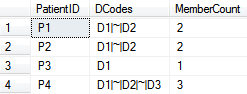
When loading the dimension we need to only include the DCodes and MemberCount fields. We also need to apply the distinct function to ensure duplicate DCodes are not included such as is the case with PatientID P1 & P2. This I easily accomplished in LeapFrogBI by checking the distinct option in the filter definition for the dimension.
With the diagnosis group dimension in place we can now load the fact table. The foreign key lookup from Fact_Event to Dim_DiagnosisGroup is accomplished by joining on the DCodes. Currently the primary fact table source (Patient_Event) does not contain a value for DCodes. Therefore, we must first join the source to the above PatientID DCodes output. In our sample case we are only concerned with the current DCodes value for each patient. Also, our patient list if small enough to generate the DCodes during each load process. However, in other scenarios it might be more efficient to create a dimension with a PatientID key and include the DCodes field set to SCD1 (current). In our sample model we already have a patient dimension so we could add this field (DCodes) to the existing dimension.
The last step is to create the bridge table. The bridge table is nothing more than a fact table with two related dimensions (diagnosis group and diagnosis). Loading the bridge table requires that we explode the diagnosis group dimension such that there is a record for each related diagnosis. This is easily accomplished by joining the two dimensions using an inner join with a charindex on the diagnosis.
SELECT [DCode], [DCodes], [MemberCount] FROM [PatientDiagnosis] a inner join dim_Diagnosis b on charindex(b.DCode,a.DCodes) > 0 Order by DCodes, DCode
Again, this is easily accomplished in LeapFrogBI. First we profile the diagnosis group dimension so we can use it as the source for our bridge table. Then, we join to the diagnosis dimension and setup the on clause to a charindex expression where > 0 such as above.
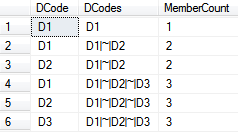
Notice the above result set includes a record for each diagnosis to diagnosis group combination. This is exactly what we need for our bridge table source. We replace the business keys with foreign keys by looking up the dimension surrogate key values. The resulting bridge table will resemble the below records.

With the bridge table in place the model is complete. Users can now easily join the fact table to the bridge to get a list of related diagnosis for each fact record. The join will be accomplished using the FK_DiagnosisGroup field on both the fact table and the bridge table.
Bridge tables provide a map between fact tables and dimensions that are at a lower grain. Key to building a bridge table is the ability to convert multiple records into a string. The good news for LeapFrogBI uses is that all of the scripting is generated automatically. Developers select the desired component type and make the desired selections using a simple user interface.